Simulating Corruptions¶
The bqlearn.corruptions module in biquality-learn provides several
functions to artificially create biquality datasets by introducing
synthetic corruption. These functions can be used to simulate various
types of label noise or imbalances in the dataset. We aim to ease the
benchmark of biquality learning algorithms thanks to the corruption API,
with a special touch on the reproducibility and standardization of these
benchmarks for researchers.
Biquality Data¶
In the biquality data setup, there is no assumption on the difference in joint distribution between the two datasets, and it can cover a wide range of known problems. From the Bayes Formula:
Distribution shift covers:
covariate shift \(\mathbb{P}_T(X)\neq\mathbb{P}_U(X)\)
concept drift \(\mathbb{P}_T(Y \mid X)\neq\mathbb{P}_U(Y \mid X)\)
class-conditional shift \(\mathbb{P}_T(X \mid Y)\neq\mathbb{P}_U(X \mid Y)\)
prior shift \(\mathbb{P}_T(Y)\neq\mathbb{P}_U(Y)\).
Especially modifying both the decision boundary and the feature distribution or class balance and class-conditional feature distribution at the same time lead to particularly complex distribution shifts.
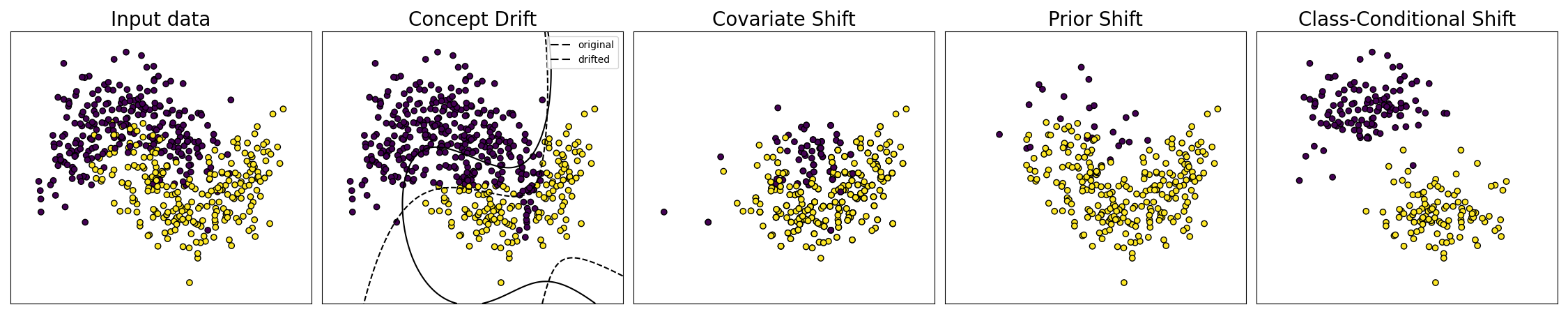
Corrupted toy dataset.¶
Corruption API¶
Here is a brief overview of the functions available in the corruption module:
make_weak_labels(): Adds weak labels to a dataset by learning a classifier on a subset of the dataset and using its predictions as a new label.make_label_noise(): Adds noisy labels to a dataset by randomly corrupting a specified fraction of the labels thanks to a given noise matrix.make_instance_dependent_label_noise(): Adds instance-dependent noisy labels by corrupting a specified fraction of the labels with a probability depending on the sample and a given noise matrix.uncertainty_noise_probability(): Computes the probability of corrupting a sample based on the predicted class probabilities of a given classifier.make_feature_dependent_label_noise(): Adds instance-dependent noisy labels by corrupting a specified fraction of the labels with a probability depending on a random linear map between the features space and the labels space.make_imbalance(): Creates an imbalanced dataset by oversampling or undersampling the minority class.make_sampling_biais(): Creates a sampling bias by sampling not at random a subset of the dataset from the original dataset. The sampling scheme follows a Gaussian distribution with a shifted mean and scaled variance computed from the first principal component of a PCA.
These functions can be used to artificially create biquality datasets for testing and evaluating biquality learning algorithms.