Note
Go to the end to download the full example code
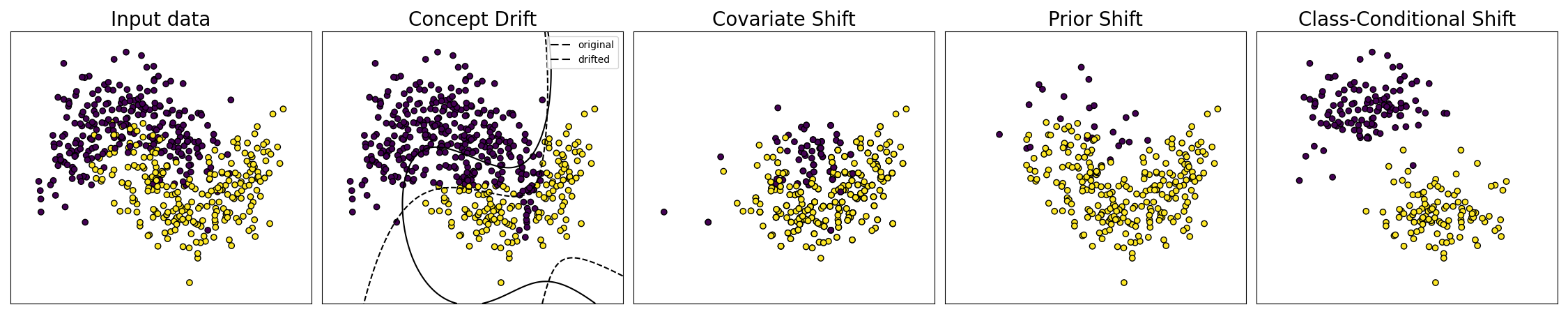
Effect of Synthetic Corruptions on Toy Dataset¶
/home/docs/checkouts/readthedocs.org/user_builds/biquality-learn/envs/latest/lib/python3.10/site-packages/sklearn/cluster/_kmeans.py:1412: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
super()._check_params_vs_input(X, default_n_init=10)
/home/docs/checkouts/readthedocs.org/user_builds/biquality-learn/envs/latest/lib/python3.10/site-packages/sklearn/cluster/_kmeans.py:1412: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
super()._check_params_vs_input(X, default_n_init=10)
import matplotlib.pyplot as plt
import numpy as np
from sklearn import clone
from sklearn.datasets import make_moons
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from bqlearn.corruptions import (
make_cluster_imbalance,
make_imbalance,
make_instance_dependent_label_noise,
make_sampling_biais,
noisy_leaves_probability,
)
seed = 2
names = [
"Concept Drift",
"Covariate Shift",
"Prior Shift",
"Class-Conditional Shift",
]
corruptions = [
lambda X, y: (
X,
make_instance_dependent_label_noise(
noisy_leaves_probability(
X,
y,
noise_ratio=0.5,
purity="descending",
min_samples_leaf=20,
random_state=seed,
),
y,
"background",
random_state=seed,
),
),
lambda X, y: make_sampling_biais(X, y, a=2, b=4, random_state=seed),
lambda X, y: (
make_imbalance(y, X, majority_ratio=10, random_state=seed)[1],
make_imbalance(y, X, majority_ratio=10, random_state=seed)[0],
),
lambda X, y: make_cluster_imbalance(
X, y, per_class_n_clusters=3, majority_ratio=10, random_state=seed
),
]
n_samples = 500
n_classes = 2
datasets = [
make_moons(n_samples=n_samples, noise=0.3, random_state=0),
]
figure = plt.figure(figsize=(4.5 * (len(corruptions) + 1), 4.5 * len(datasets)))
i = 1
# iterate over datasets
for ds_cnt, ds in enumerate(datasets):
# preprocess dataset, split into training and test part
X, y = ds
X = StandardScaler().fit_transform(X)
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
h = 0.02
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
ax = plt.subplot(len(datasets), len(corruptions) + 1, i)
if ds_cnt == 0:
ax.set_title("Input data", fontsize=20)
# Plot the input points
ax.scatter(X[:, 0], X[:, 1], c=y, edgecolors="k")
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xticks(())
ax.set_yticks(())
i += 1
# iterate over corruptions
for name, corruption in zip(names, corruptions):
ax = plt.subplot(len(datasets), len(corruptions) + 1, i)
X_corrupted, y_corrupted = corruption(X, y)
# Plot the corrupted data
ax.scatter(
X_corrupted[:, 0],
X_corrupted[:, 1],
c=y_corrupted,
edgecolors="k",
)
if name == "Concept Drift":
clf = SVC(kernel="poly", degree=3, coef0=1)
clean_clf = clone(clf).fit(X, y)
drift_clf = clone(clf).fit(X_corrupted, y_corrupted)
Z_clean = clean_clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z_clean = Z_clean.reshape(xx.shape)
Z_drift = drift_clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z_drift = Z_drift.reshape(xx.shape)
c1 = ax.contour(xx, yy, Z_clean, levels=0, colors="black")
c2 = ax.contour(
xx, yy, Z_drift, levels=0, linestyles="dashed", colors="black"
)
h1, _ = c1.legend_elements()
h2, _ = c2.legend_elements()
ax.legend([h1[0], h2[0]], ["original", "drifted"])
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xticks(())
ax.set_yticks(())
if ds_cnt == 0:
ax.set_title(name, fontsize=20)
i += 1
plt.tight_layout()
plt.show()
Total running time of the script: (0 minutes 0.826 seconds)