Note
Go to the end to download the full example code
Learning with Noisy Labels¶
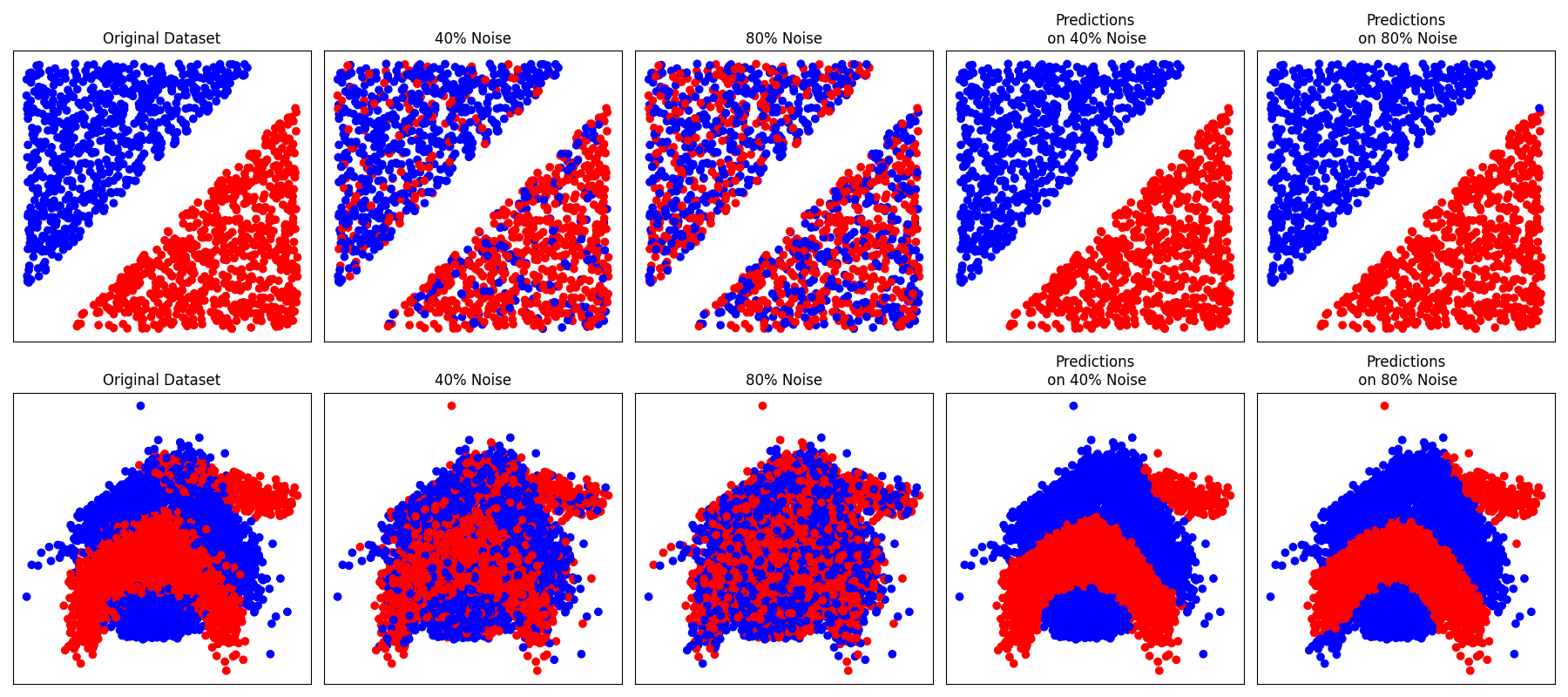
This example shows how to reproduce Figures 1 and 2 from the article : “Learning with Noisy Labels” by Natarajan and al.
/home/docs/checkouts/readthedocs.org/user_builds/biquality-learn/envs/stable/lib/python3.10/site-packages/biquality_learn-0.0.1-py3.10.egg/bqlearn/unbiased.py:179: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
/home/docs/checkouts/readthedocs.org/user_builds/biquality-learn/envs/stable/lib/python3.10/site-packages/biquality_learn-0.0.1-py3.10.egg/bqlearn/unbiased.py:179: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
/home/docs/checkouts/readthedocs.org/user_builds/biquality-learn/envs/stable/lib/python3.10/site-packages/biquality_learn-0.0.1-py3.10.egg/bqlearn/unbiased.py:179: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
/home/docs/checkouts/readthedocs.org/user_builds/biquality-learn/envs/stable/lib/python3.10/site-packages/biquality_learn-0.0.1-py3.10.egg/bqlearn/unbiased.py:179: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
import matplotlib.pyplot as plt
import numpy as np
from numpy.random import RandomState
from sklearn.datasets import fetch_openml
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
from sklearn.svm import SVC
from bqlearn.corruptions import make_label_noise
from bqlearn.corruptions.noise_matrices import uniform_noise_matrix
from bqlearn.unbiased import LossCorrection
n_samples = 2000
seed = 0
X = RandomState(seed).rand(n_samples, 2)
y = np.empty(n_samples)
margin = 0.15
y = np.delete(y, (X[:, 1] < X[:, 0] + margin) * (X[:, 1] > X[:, 0] - margin))
X = np.delete(X, (X[:, 1] < X[:, 0] + margin) * (X[:, 1] > X[:, 0] - margin), axis=0)
y[X[:, 1] > X[:, 0] + margin] = 0
y[X[:, 1] < X[:, 0] - margin] = 1
figure_1 = (X, y)
figure_2 = fetch_openml(data_id=1460, return_X_y=True, parser="pandas", as_frame=False)
datasets = [figure_1, figure_2]
clfs = [LogisticRegression(random_state=1), SVC(probability=True)]
cmap = plt.cm.bwr
figure = plt.figure(figsize=(18, 8))
for i, (clf, (X, y)) in enumerate(zip(clfs, datasets)):
y = LabelEncoder().fit_transform(y)
ax = plt.subplot(len(datasets), 5, 1 + 5 * i)
ax.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap)
ax.set_title("Original Dataset")
ax.set_xticks(())
ax.set_yticks(())
noise_matrix = uniform_noise_matrix(2, 0.4)
y_corrupted = make_label_noise(y, noise_matrix, random_state=seed)
ax = plt.subplot(len(datasets), 5, 2 + 5 * i)
ax.scatter(X[:, 0], X[:, 1], c=y_corrupted, cmap=cmap)
ax.set_title("40% Noise")
ax.set_xticks(())
ax.set_yticks(())
unbiased = LossCorrection(clf, transition_matrix=noise_matrix)
unbiased.fit(X, y_corrupted)
ax = plt.subplot(len(datasets), 5, 4 + 5 * i)
ax.scatter(X[:, 0], X[:, 1], c=unbiased.predict(X), cmap=cmap)
ax.set_title("Predictions\n on 40% Noise")
ax.set_xticks(())
ax.set_yticks(())
noise_matrix = uniform_noise_matrix(2, 0.8)
y_corrupted = make_label_noise(y, noise_matrix, random_state=seed)
ax = plt.subplot(len(datasets), 5, 3 + 5 * i)
ax.scatter(X[:, 0], X[:, 1], c=y_corrupted, cmap=cmap)
ax.set_title("80% Noise")
ax.set_xticks(())
ax.set_yticks(())
unbiased = LossCorrection(clf, transition_matrix=noise_matrix)
unbiased.fit(X, y_corrupted)
ax = plt.subplot(len(datasets), 5, 5 + 5 * i)
ax.scatter(X[:, 0], X[:, 1], c=unbiased.predict(X), cmap=cmap)
ax.set_title("Predictions\n on 80% Noise")
ax.set_xticks(())
ax.set_yticks(())
plt.tight_layout()
plt.show()
Total running time of the script: ( 0 minutes 13.579 seconds)