Radon-Nikodym Derivative¶
In the Empirical Risk Minimization (ERM) framework, when learning a classifier \(f:\mathcal{X}\rightarrow \mathcal{Y}\), we seek to minimize its risk \(R(f)\) given a loss function \(L:\mathcal{Y}^2\rightarrow \mathbb{R}\):
However, when the true distribution \(T\) cannot be observed because of weaknesses of supervision or dataset shifts, we can rewrite given the observed distribution \(U\):
Thus, in order to minimize the true risk of the classifier on the true but unobserved distribution, we need to reweight the loss function on the observed distrbution by \(\mathbb{P}_T(X,Y)/\mathbb{P}_U(X,Y)\). This measure is called the Radon-Nikodym Derivative (RND) of \(\mathbb{P}_U(X,Y)\) with respect to \(\mathbb{P}_U(X,Y)\). Assuming that \(\mathbb{P}_T(X,Y)\) is absolutely continuous with respect to \(\mathbb{P}_U(X,Y)\), then the RND exists and is unique.
This reweighting scheme has particularly inspired the literature of covariate shift, and many algorithms have been implemented to estimate the RND, regrouped in an umbrella named Density Ratio Estimators.
However, estimating the RND can be a difficult task, especially in the case of distribution shift where the joint distribution ratio needs to be estimated. Proposals have been made to ease this estimation.
Importance Reweighting for Biquality Learning¶
A first approach is to focus on the concept drift between datasets using the Bayes Formula:
This approach is implemented in bqlearn.irbl.IRBL where both conditional
distributions are estimated using two calibrated classifiers [NLBC2021].
It is also implemented in bqlearn.irlnl.IRLNL (see Noise Transition Matrices).
To be noted that none of the implemented algorithms estimates the ratio of features distribution.
K-Density Ratio¶
A second approach is to focus on the class-conditional covariate shift between datasets using the Bayes Formula differently:
With this approach, the joint density ratio estimation task has been decomposed into \(K\)-tasks where \(K\) is the number of classes to predict. For each class, only samples of the given class \(y\) are selected on both datasets, such that the samples are drawn from the \(\mathbb{P}(X \mid Y=y)\) distribution. Then, a density ratio estimation procedure is used on these sub-datasets to estimate \(\mathbb{P}_T(X \mid Y=y)/\mathbb{P}_U(X \mid Y=y)\). When repeated on all classes, this approach does handle distribution shifts.
This approach is implemented in KPDR [NLBC2023] and KKMM [FNS2020] with
two different density ratio estimation algorithms, pdr() [BBS2007] and kmm() [HSGBS2006] respectively.
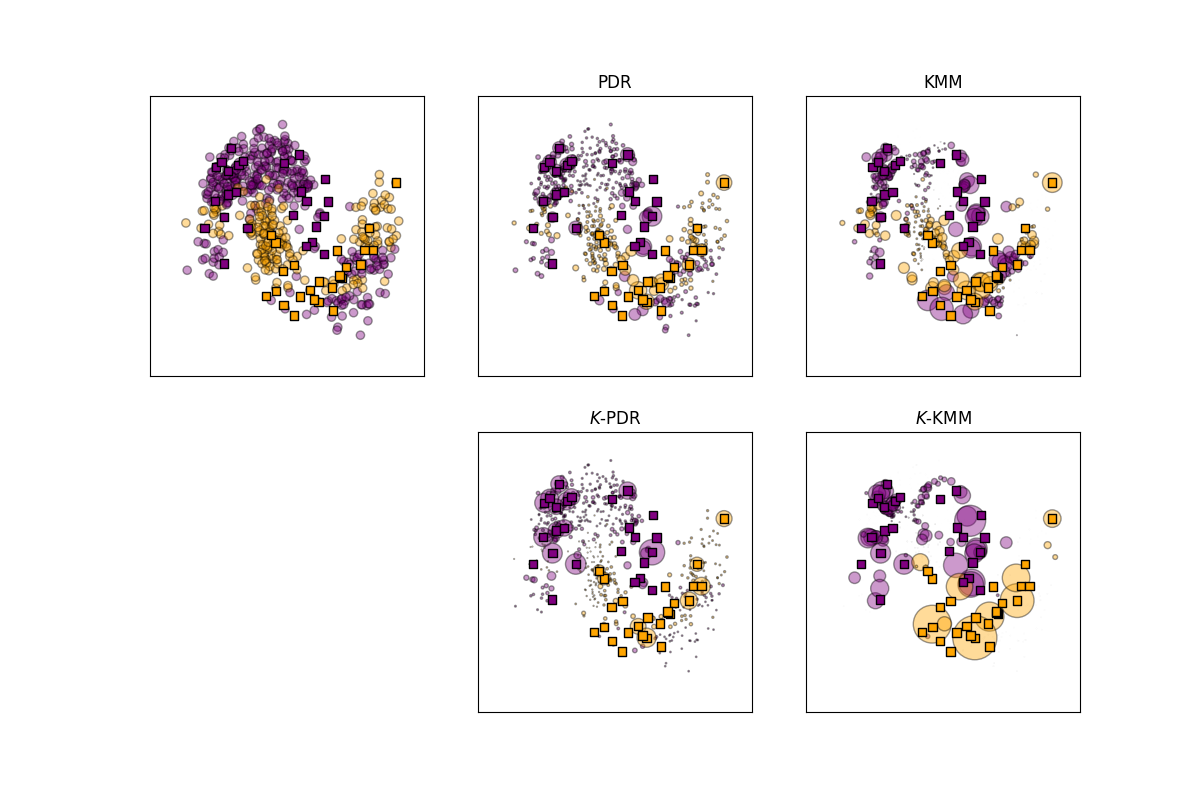
Illustration of the reweighting mechanisms behind K-Density Ratio.¶
The above figures shows how pdr() and kmm() by design can’t take into account label noise, only subsampling biais.
However, KPDR and KKMM are able to deal with distribution shifts on this toy dataset.
Moreover, KKMM implement a batched version for scalability [YAM2015].
Loss based Density Ratio¶
A third approach is to focus on the density ratio estimation task by finding a deterministic and invertible transformation \(f\):
An example of such transformation \(f\) is the classification loss of a model learned on the biquality data.
This approach is implemented in IPDR [L2018] and IKMM [FNS2020].
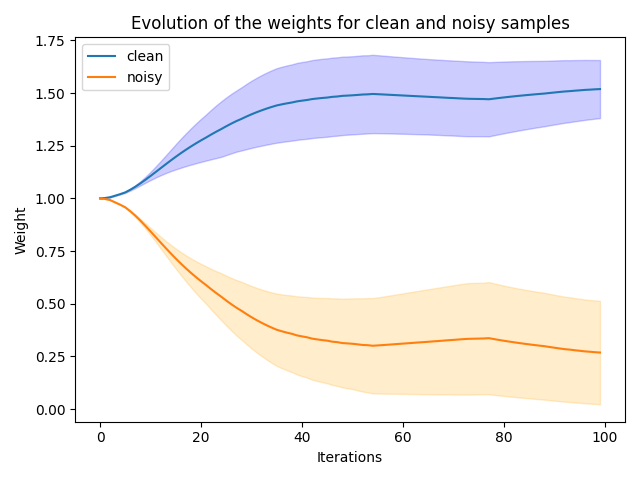
Evolution of the weights computed by IPDR for clean and noisy samples on a toy dataset corrupted with label noise.¶
IPDR and IKMM use a windowing approach where losses from previous iterations can be used
in addition to the current loss to estimate the density ratio. It allows to recover algorithms such as MentorNet [L2018] with IPDR.