Note
Go to the end to download the full example code
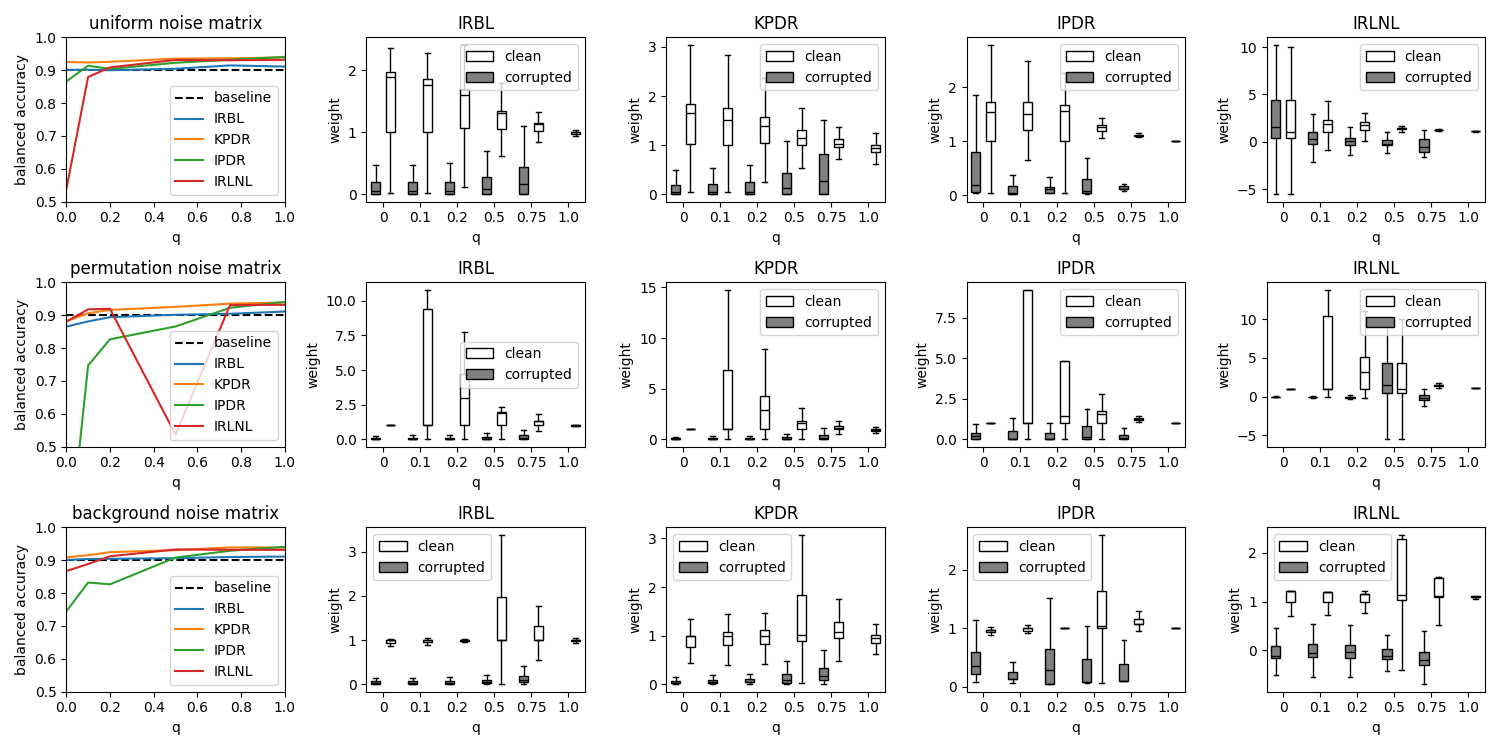
Importance Reweighthing Efficiency Against Different Noise Models¶
/home/docs/checkouts/readthedocs.org/user_builds/biquality-learn/envs/latest/lib/python3.10/site-packages/biquality_learn-0.0.3.dev7-py3.10.egg/bqlearn/irlnl.py:240: RuntimeWarning: divide by zero encountered in divide
import matplotlib.pyplot as plt
import numpy as np
from sklearn.calibration import CalibratedClassifierCV
from sklearn.compose import make_column_selector, make_column_transformer
from sklearn.datasets import fetch_openml
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.metrics import balanced_accuracy_score
from sklearn.model_selection import StratifiedShuffleSplit, train_test_split
from sklearn.preprocessing import LabelEncoder, OrdinalEncoder
from bqlearn.corruptions import make_label_noise
from bqlearn.density_ratio import IPDR, KPDR
from bqlearn.irbl import IRBL
from bqlearn.irlnl import IRLNL
seed = 2
clf = HistGradientBoostingClassifier(max_iter=10, warm_start=True, random_state=seed)
calibrated_clf = CalibratedClassifierCV(clf, method="isotonic", n_jobs=-1)
names = ["IRBL", "KPDR", "IPDR", "IRLNL"]
classifiers = [
IRBL(calibrated_clf, clf),
KPDR(clf, pdr_estimator=calibrated_clf, n_jobs=-1),
IPDR(
clf,
n_estimators=10,
exploit_iterative_learning=True,
pdr_estimator=calibrated_clf,
),
IRLNL(calibrated_clf, clf, transition_matrix="gold", n_jobs=-1),
]
X, y = fetch_openml(data_id=4534, parser="pandas", return_X_y=True)
categorical_features_selector = make_column_selector(dtype_include=[object, "category"])
X = make_column_transformer(
(
OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=np.nan),
categorical_features_selector,
),
remainder="passthrough",
).fit_transform(X)
y = LabelEncoder().fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=seed, stratify=y
)
trusted, untrusted = next(
StratifiedShuffleSplit(train_size=0.1, random_state=seed).split(X_train, y_train)
)
sample_quality = np.ones_like(y_train)
sample_quality[untrusted] = 0
noise_matrices = ["uniform", "permutation", "background"]
qs = [0, 0.1, 0.2, 0.5, 0.75, 1.0]
trusted_perf = balanced_accuracy_score(
clf.fit(X_train[trusted], y_train[trusted]).predict(X_test), y_test
)
figure = plt.figure(figsize=(3 * (len(classifiers) + 1), 2.5 * len(noise_matrices)))
ticks = 2 * np.array(range(0, len(qs), 1))
clean_dict = {
"patch_artist": True,
"boxprops": dict(facecolor="white", color="black"),
"capprops": dict(color="black"),
"flierprops": dict(color="black"),
"medianprops": dict(color="black"),
"whiskerprops": dict(color="black"),
}
clean_position = ticks + 0.4
noisy_dict = {
"patch_artist": True,
"boxprops": dict(facecolor="gray", color="black"),
"capprops": dict(color="black"),
"flierprops": dict(color="black"),
"medianprops": dict(color="black"),
"whiskerprops": dict(color="black"),
}
noisy_position = ticks - 0.4
n_rows = len(noise_matrices)
n_columns = 1 + len(classifiers)
for i, noise_matrix in enumerate(noise_matrices):
ax = plt.subplot(n_rows, n_columns, (n_columns) * i + 1)
ax.axhline(trusted_perf, color="black", linestyle="--", label="baseline")
for j, (name, classifier) in enumerate(zip(names, classifiers)):
axhist = plt.subplot(n_rows, n_columns, (n_columns) * i + j + 2)
perfs = []
clean_weights = []
noisy_weights = []
for q in qs:
if q == 0 and (noise_matrix == "flip" or noise_matrix == "background"):
q = 0.05
y_corrupted = np.copy(y_train)
y_corrupted[untrusted] = make_label_noise(
y_train[untrusted],
noise_matrix=noise_matrix,
noise_ratio=1 - q,
random_state=seed,
)
classifier.fit(X_train, y_corrupted, sample_quality=sample_quality)
perf = balanced_accuracy_score(classifier.predict(X_test), y_test)
perfs.append(perf)
if hasattr(classifier, "sample_weight_"):
if classifier.sample_weight_.ndim > 1:
sample_weight = classifier.sample_weight_[:, 0]
else:
sample_weight = classifier.sample_weight_
else:
sample_weight = classifier.sample_weights_[:, -1]
clean_weights.append(sample_weight[y_corrupted == y_train])
noisy_weights.append(sample_weight[y_corrupted != y_train])
noisy_bp = axhist.boxplot(
noisy_weights, showfliers=False, positions=noisy_position, **noisy_dict
)
clean_bp = axhist.boxplot(
clean_weights, showfliers=False, positions=clean_position, **clean_dict
)
axhist.legend(
[clean_bp["boxes"][0], noisy_bp["boxes"][0]], ["clean", "corrupted"]
)
axhist.set_title(label=f"{name}")
axhist.set_xlabel("q")
axhist.set_ylabel("weight")
axhist.set_xticks(ticks, sorted(qs))
ax.plot(qs, perfs, label=name)
ax.legend()
ax.set_title(label=f"{noise_matrix} noise matrix")
ax.set_xlabel("q")
ax.set_ylabel("balanced accuracy")
ax.set_ylim((0.5, 1))
ax.set_xlim((0, 1))
plt.tight_layout()
plt.show()
Total running time of the script: (1 minutes 13.633 seconds)